At the Researcher to Reader Conference ( R2R) 21-22 Feb 2017 we held a Workshop on ‘Which Standards Matter and Why.’ This is the second time I’ve attended the conference and two things stood out for me again – the mix of Publishers and Librarians and the enthusiasm and hard work of the delegates for the workshops. The former is very refreshing as it creates an environment for some of the contentious issues around OA publishing in particular to be discussed in less adversarial terms than happens perhaps online via blogs and mailing lists.
The workshop posed the question in relation to existing, emerging and missing standards : ‘How can research libraries, publishers and their intermediaries co-operate to solve some of the ‘pain points’ in rapidly evolving scholarly communications processes?’
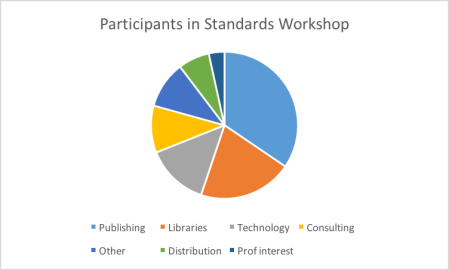
We had 29 attendees from publishing, libraries, technical/standards bodies, and others.
We held 3 meetings over the two days of the conference:
Meeting 1 : Setting Scene – Collecting information – a post-it exercise to identify, describe and gauge awareness in/usage of as many standards as we could.
We collected standards in categories including Identifiers, Definitions; Lists/Taxonomies; Data Models; Policies & Other.
What was clear from the group was that Identifiers were the most well known and there is high engagement with ORCID, DOI/Crossref and ISBN/ISNI but split engagement across the various Organisational Identifier initiatives i.e. ISNI, RINGGOLD & Digital Science’s GRID. The FundREF finding is also interesting as many people are thinking about using/planning to use it, but none yet are.
Meeting 2: Standards in publishing process; usage and gaps/pain points
We concentrated on journal article publishing given that this was the process familiar to most of our participants. This was simplified down to the following basic steps:
With the payment positioned somewhere along the line …. and here we mean paying APCs.
| Pain Points : Where standards could help in the (article) publishing process | |||
| Submit | Review | Publish | Payment |
| No consistency of instructions to authors | Identifying reviewers and being able to check they are who they say they are (certify); no robust registry of reviewers | Many different licences misunderstood by authors | Difficult to determine who pays |
| No standard information requirements for manuscript submission | Review process is based on original paper-based one – to- one process rather than a collaborative process taking advantage of new technology | No standard information requirements for acceptance notification to authors | No standard information requirements for invoice – critical for efficient process and quality data |
| No open persistent ID allocated at submission | Little/no? recognition of Reviewer role – although issues around blindness | Not all deposits to pubmed are automated | Different publisher models/offers – lack of transparency at point in process required |
| Inconsistent times across sector for process – should there be standards we adhere to i.e. review within x days? | No consistent link to pre-print where it exists online | Lots of point to point interactions; many publishers with many journals dealing with many many authors and many libraries. | |
| Reviewer training – standards? | |||
Meeting 3: Priorities & Actions
Identifying what standards relevant or required to relieve the ‘pain points’. The solutions we discussed divided into three broad categories: (i) further use cases for existing standards. (ii) working groups to tackle missing standards around key exchange points and (iii) broader guidance/best practice development.
So looking at identifiers – where can these be further embedded in the process?
- DOI – allocate as early as possible so why not at manuscript submission? Ok it may not be published by that publisher or even at all but is that really a problem compared to the advantage of having a persistent identifier allocated up front to ease the workflow down the line? Note : Crossref and Datacite are the two main places scholarly content is registered to get DOI.
- ORCID – require reviewers to have an ORCID – to help ensure are who they say they are and give context. Interestingly after the workshop I then saw the blog post at ttps://orcid.org/blog/2016/09/22/recognizereview-orcid
- Organisation ID – no single standard established yet – needs to be. Work is progressing in this area see https://www.crossref.org/blog/the-organization-identifier-project-a-way-forward/
- Crossref Funding Data (formerly FundREF) – related to 3 to get organisational identifiers but also need authority file for grant/project references as reporting needs to be to the project level not just the funder.
And what about new standards? Two areas stood out:
- Standard information required for APC invoice – initial thoughts from the group:
- DOI (should be created early – why not on submission?)
- ORCID for (at least) corresponding author
- Institutional identifier for (at least) corresponding author – ISNI or Ringgold or GRID
- ISSN
- Publisher identifier – ISNI or Ringgold or GRID?
- Itemised – APC, page charges, colour charges
- Funder identifier/s – Crossref Funding Data (https://www.crossref.org/community/funders/)
- Project identifier/s
- Standard information required for manuscript submission.
And, finally the broader guideline development:
- Reviewer training – we heard at the conference plenary that several publishers do provide this; it would be good to know more about what they do and whether best practice guidelines are available to share.
- Instructions to authors & expected standards of service; what is expected from the author and what they will receive in return included expected timeframes, technical requirements, funder compliance alignment, costs ….
Much of what we found came as no surprise – areas such as need for persistent Organisation Identifiers – and work is underway involving the wider research sector. But some are things that have not yet started to be addressed and there was a real expression from the workshop that these should be tackled through a mechanism such as a CASRAI working group or similar.
We welcome feedback and offers to help take any of the above forward as this needs to be done collaboratively.
Full unreport at http://bit.ly/2maXSt9
Anna Clements, Valerie McCutcheon, Tony O’Rourke, Iris Nord, Duncan Campbell, Stefanie Horsmann, Britt-Marie Wideberg, Lucy Lambe, Cecilia Heyman Widmark, Ross MacIntyre, Luisa Gaggini, Luke Davies, Cathy Holland, Ed Pentz, Sarah Bull, Jessica Rutt, Greta Boonen, Charlotte Coyte, Gareth Malcolm, Graham Walton, Judy Russell, Ginger Strader Minkiewicz, Susan King, Howard Ratner, Laura Cox, Natalia Timiraos, Christine Buckley, Anji Clarke, Sally Rumsey



 Posted by Anna Clements
Posted by Anna Clements  Subscribe to:
Subscribe to: